Tired of Okta Workflow Limits? Build a Real-Time Identity Automation with AWS & Terraform
· 15min
Introduction
At most companies I have been part of, once an Identity Provider like Okta or Entra ID is in place, the next natural step is automation. IT teams lean on iPaaS tools like Okta Workflows, Zapier, Workato and other low code platforms to streamline onboarding and offboarding processes, reduce manual intervention, and standardize identity lifecycle changes.
What happens when those workflows hit their limits? When you need richer branching logic, tighter integration with your cloud agnostic ecosystem, or proper version control around changes to your identity automations? What if you want these flows to go through the same CI, code review, or maybe you just want to elevate your infrastructure?
That is the point where low code stops being a superpower and starts becoming technical debt.
While Iv’e been intentionally upskilling on AWS and leveraging Terraform for IT operations, I hit that exact wall. As a team, we had started moving Okta itself into Terraform, and most of our infrastructure was already managed through GitLab, CI pipelines, and version control. The odd one out was our offboarding automation. It still lived inside Okta Workflows, separate from the rest of our code driven stack. That gap made it a perfect opportunity to rebuild using AWS services.
In this post I walk through how I pushed beyond that ceiling and built a real-time offboarding pipeline using AWS serverless services, wired together and managed entirely with Terraform. The goal was not to reinvent offboarding, but to replatform it. We kept the same Slack based alerting pattern from Okta Workflows, while moving the underlying automation into an event driven AWS pipeline that treats identity lifecycle events as first class signals and still surfaces them in #offboarding-okta-alerts for monitoring.
Why Move Beyond Low Code For Offboarding
Low code tools like Okta Workflows are absolutely the right answer for a ton of 10/10 IT Administration use cases. They are optimized for speed, accessibility, and plenty of community documentation around getting started templates. Most teams end up with their onboarding and offboarding flows living there because it is close to the source of truth and supports native connectors for most modern SaaS apps.
As the environment matures though, requirements can start to look more like platform engineering and less like workflow wiring:
-
You need more expressive control flow, nested conditions, routing and branching that quickly becomes unreadable in a visual editor
-
You want to integrate with internal AWS services that do not exist as off the shelf connectors
-
You might want your identity automation to be declared as code, peer reviewed, and promoted throughout your team
That last point became the inspiration behind this project. We needed an offboarding workflow that still felt like a real time Okta flow, but lived in AWS instead. It had to be observable, with logs and metrics wired into our existing tooling, repeatable through Terraform, and easy to extend with new downstream actions as requirements changed. On top of that, we wanted the flexibility to plug in dynamic REST API integrations with other service providers without redesigning the whole thing every time.
Okta can still be the source of truth for identity. But the processing and declaritive orchestration approach will need to live in AWS.
Let’s dive in
This is a classic event driven pattern. Source system emits our events, EventBridge provides routing, SQS handles durability, and Lambda is the execution layer.
Here is the vision of our project:
-
The Trigger: An admin suspends or deactivates a user in Okta. (In prod, this would look like an HRIS trigger from an external SaaS integration. For this project, this is done manually in Okta by the Admin to keep the example simple)
-
Event Stream: Okta Log Streaming pushes the corresponding system log event into an AWS EventBridge partner event bus.
-
Routing and Filtering: EventBridge then applies a rule to match only the identity lifecycle events we care about.
-
Durable Buffer: Matching events are published to an SQS queue that acts as a reliability and back pressure layer.
-
Serverless Worker: A Python based Lambda function consumes messages from SQS, transforms them into a Slack friendly payload, and posts into the target channel.
Prerequisites
To build this project end-to-end, you should have some things prepared:
-
An AWS Account: With rights to create EventBridge, SQS, IAM, and Lambda resources, and a way for Terraform to authenticate, for example IAM access and secret keys or an assumed role
-
An Okta API Token: You can generate this in your Okta Admin console under Security -> API -> Tokens
-
Familiarity with Terraform basics: I’ll assume you’re comfortable with the basics of defining providers and applying Terraform configurations
-
A Slack app: The Lambda function will post into a dedicated Slack channel. That requires a Slack app with appropriate scopes and a bot token. Let’s dive in!
Step 1/ Turn Okta Logs Into Targeted Offboarding Events
The foundation of this whole workflow is the fact that Okta can act as an event source.
Instead of polling the Okta API on a schedule, we let Okta push its System Log Events directly into AWS using Log Streaming. Under the hood, Okta treats AWS EventBridge as a native streaming target, and AWS exposes this as a partner event bus dedicated to Okta.
This gives you two big benefits:
- Near real time delivery: Identity events land in AWS within seconds of the admin action
- Centralized telemetry: Once the events are in AWS, you can fan them out to CloudWatch, S3, Slack or whatever logging stack you already use to enhance your observability.
This log streaming feature is the foundation. It not only powers our workflow but also opens doors for centralized logging like what we mentioned above for long-term retention and compliance.
In our lab, you might think to jump straight into the Okta and AWS consoles (Add an AWS EventBridge log stream), add an EventBridge log stream, and tweak settings until it works. In our case, you want Terraform in front of all that. So the first thing I do is set up providers for Okta and AWS so Terraform becomes the foundation.
With that in mind, here is the provider setup that the rest of this KB builds on.
terraform {
required_providers {
okta = {
source = "okta/okta"
version = "~> 6.3.0"
}
}
}
provider "okta" {}
# Terraform will pass arguments env vars from Doppler and inject secrets into the environment
# AWS provider
provider "aws" {
region = "us-west-1"
}-
An Okta provider block that pulls credentials from environment variables (in my case, injected by Doppler)
-
An AWS provider block that pins the region for all of the EventBridge, SQS, IAM, and Lambda resources that follow.
With our providers in place, now we can move onto configuring the integration between Okta and AWS to enable our log streaming feature.
This will help us to accept partner events from Okta.
# Okta Log Stream
resource "okta_log_stream" "okta_to_eventbridge" {
name = "okta-eventbridge"
type = "aws_eventbridge"
status = "ACTIVE"
settings {
account_id = var.aws_account_id
region = "us-west-1"
event_source_name = "okta_log_stream"
}
}
# Okta creates a partner source in AWS named:
# aws.partner/okta.com/<org-segment>/<event_source_name>
# The <org-segment> is typically your Okta org (e.g., dev-123456) or the exact
# value Okta shows in the AWS console when the source appears.
variable "okta_partner_org_segment" {
description = "Okta org segment used by the partner event source (e.g., dev-123456)."
type = string
default = "trial-6101116"
}
locals {
partner_event_source_name = "aws.partner/okta.com/${var.okta_partner_org_segment}/${okta_log_stream.okta_to_eventbridge.settings.event_source_name}"
# aws.partner/okta.com/trial-6101116/okta_log_stream, is what's in AWS
}
# Event bus that accepts the Okta partner event source
# aws_cloudwatch_event_bus = EventBridge event bus
resource "aws_cloudwatch_event_bus" "okta_partner_bus" {
name = local.partner_event_source_name
event_source_name = local.partner_event_source_name
depends_on = [okta_log_stream.okta_to_eventbridge]
}
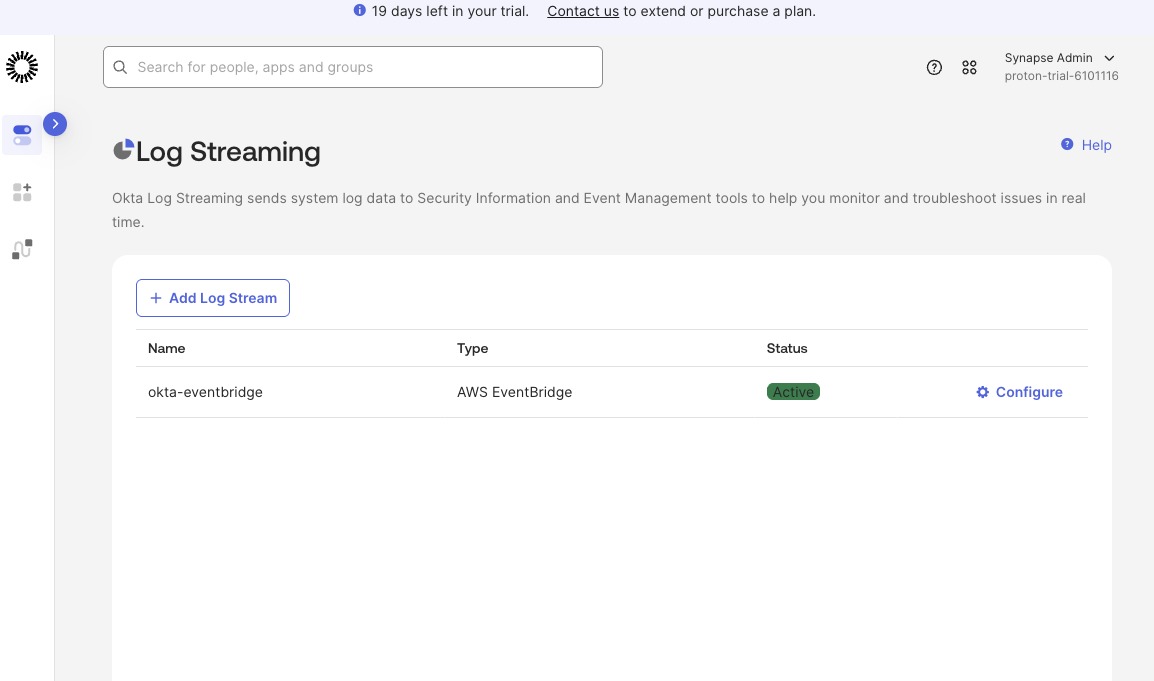
The log stream that you applied should appear on the Log Streaming page with its status as Active.
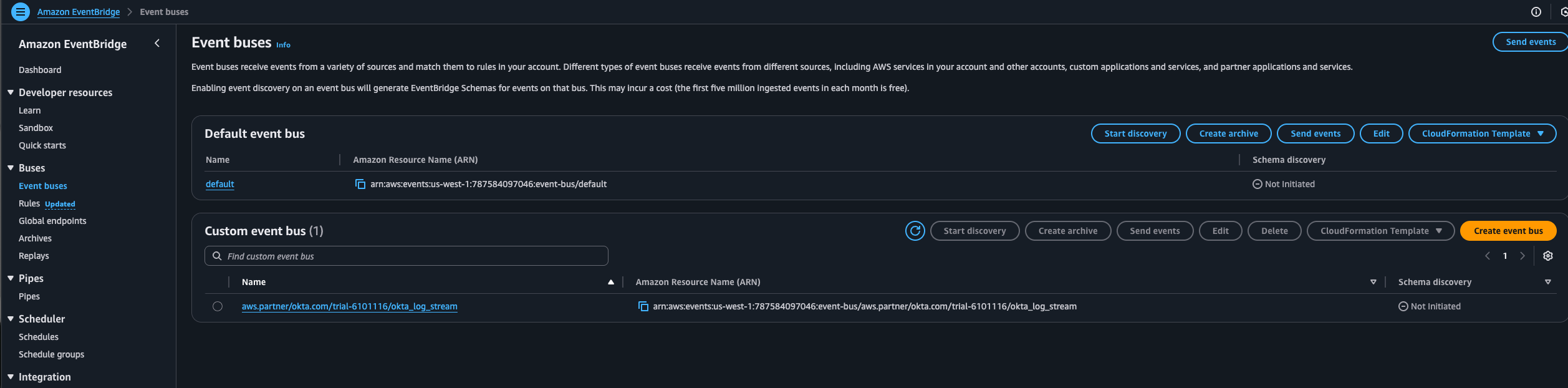
With Terraform applied, if you also look in the AWS console, for me its us-west-1, you should now see an EventBridge event bus named aws.partner/okta.com/
Step 2/ Filter Identity Lifecycle Events With AWS EventBridge
Once Log Streaming is enabled, the EventBridge bus turns into a firehose of Okta telemetry. Every authentication, policy evaluation, app assignment, and admin action shows up there. Useful, but not all of it is relevant to our offboarding automation.
For this project, we only care about a tiny slice of that stream. user suspensions and deactivations. That is where EventBridge rules come in.
An EventBridge rule lets you declaratively match on the shape of incoming events and forward only the ones you care about to downstream targets. In our case, the rule is scoped to the Okta partner event bus as the source and system log events where the eventType is user.lifecycle.suspend or user.lifecycle.deactivate. Everything else stays on the bus and never reaches SQS or Lambda.
The nice part is that this pattern is reusable. If you ever want to extend it beyond IT offboarding, you can target other event types without changing the architecture. For example, you could:
- Watch authentication events such as user.session.start, policy.evaluate_sign_on, or user.authentication.verify to drive security analytics
- Track application events like user.app.assign to understand when access to critical apps changes
- Monitor policy, admin, or system events such as rate limit warnings or high risk configuration changes
- React to device or group events if you want to tie identity changes to device posture or group membership
The key is that EventBridge gives you a central place to express those routing rules. You decide which Okta events become first class signals in AWS, and the rest of the pipeline stays exactly the same.
You can think of this rule as a routing policy living at the edge of your AWS account. It ensures that only the identity lifecycle events you care about leave the bus and enter the queue. This keeps the rest of the pipeline intentionally small and focused.
With the AWS provider & Log Streaming Connector from Okta to AWS already configured and initialized, we can now start declaring EventBridge rules that sit in front of our offboarding pipeline.
# Event rule on the PARTNER bus (filters for user suspend -> deactivate)
# aws_cloudwatch_event_rule = EventBridge rule
resource "aws_cloudwatch_event_rule" "okta_user_status_changes" {
name = "okta-user-status-changes"
description = "Route Okta user suspend/deactivate events to SQS"
event_bus_name = aws_cloudwatch_event_bus.okta_partner_bus.name
event_pattern = jsonencode({
"detail" : {
"eventType" : [
"user.lifecycle.suspend",
"user.lifecycle.deactivate"
]
}
})
}
# Target Rule
# aws_cloudwatch_event_target = EventBridge target
resource "aws_cloudwatch_event_target" "okta_user_status_changes_to_sqs" {
rule = aws_cloudwatch_event_rule.okta_user_status_changes.name
event_bus_name = aws_cloudwatch_event_bus.okta_partner_bus.name
target_id = "send-to-sqs"
arn = aws_sqs_queue.okta_alerts.arn
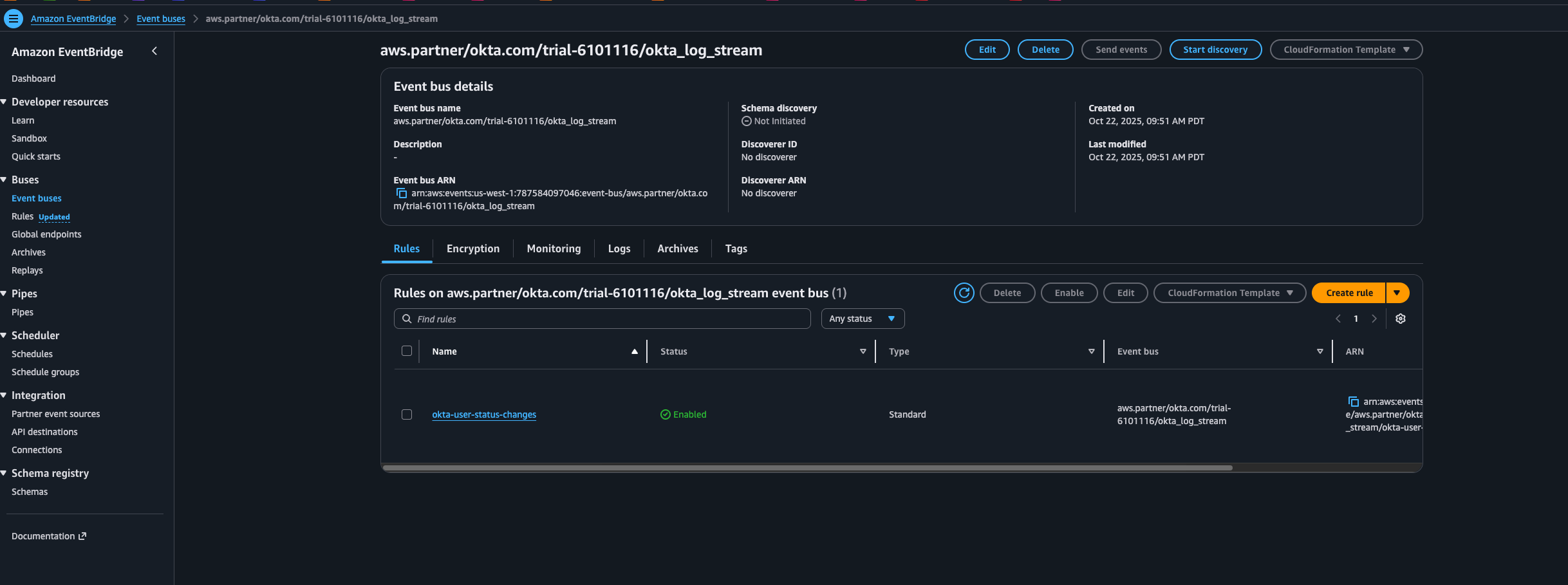
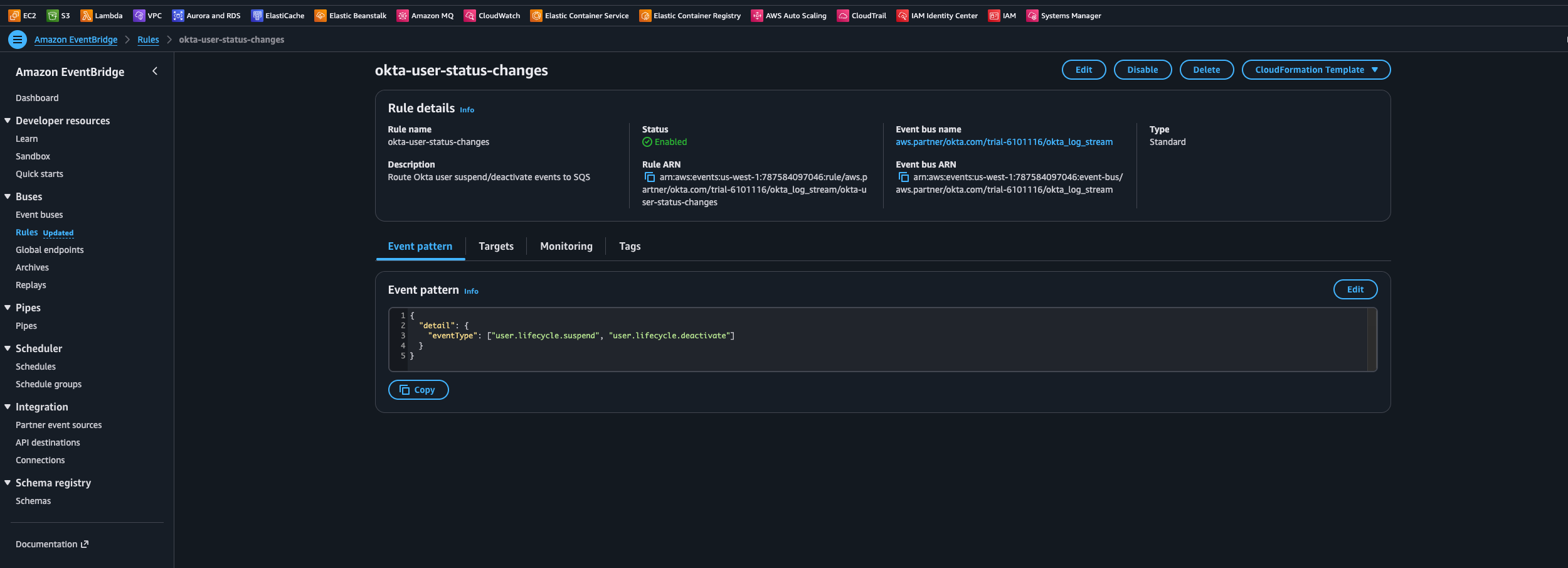
}The JSON event_pattern configures an EventBridge rule called okta-user-status-changes. That rule listens to the Okta partner bus and forwards only the user lifecycle events we care about into SQS. In this case, the pattern is scoped to user.lifecycle.suspend and user.lifecycle.deactivate. Once the Terraform configuration is applied, you can see this rule in EventBridge with those filters in place.
Step 3/ Add Reliability With SQS
You could wire the EventBridge rule directly to Lambda. For low volume or non critical flows, that is a perfectly valid design. For anything that touches offboarding and security signals, it is worth adding a durability layer.
AWS SQS solves several operational problems in our workflow:
- Transient failures: If the Slack API is down or throttling, messages stay in the queue until the Lambda can successfully process them
- Traffic spikes: If you have a large offboarding event or a bulk action, SQS smooths out the load and lets Lambda scale at its own pace
- Retries and visibility: You can control how long messages stay invisible after a failed attempt and how many times they can be retried before going to a dead letter queue
Now, let’s add an SQS queue that acts as the communication layer between EventBridge and Lambda.
# SQS queue target
resource "aws_sqs_queue" "okta_alerts" {
name = "okta-alerts"
message_retention_seconds = 1209600 # 14 days, tweak as needed
}
# Allow EventBridge rule to send to SQS
data "aws_iam_policy_document" "sqs_from_eventbridge" {
statement {
effect = "Allow"
actions = ["sqs:SendMessage"]
principals {
type = "Service"
identifiers = ["events.amazonaws.com"]
}
resources = [aws_sqs_queue.okta_alerts.arn]
condition {
test = "ArnEquals"
variable = "aws:SourceArn"
values = [aws_cloudwatch_event_rule.okta_user_status_changes.arn]
}
}
}
resource "aws_sqs_queue_policy" "okta_alerts_policy" {
queue_url = aws_sqs_queue.okta_alerts.id
policy = data.aws_iam_policy_document.sqs_from_eventbridge.json
}
With our terraform implementations, we are:
-
Creating an SQS queue (okta-alerts) with 14-day message retention to ensure events persist through processing failures
-
Configuring secure access through an IAM policy that only allows our specific EventBridge rule to send messages to the queue
-
Establishing service authentication using conditions that verify the message source, preventing unauthorized access to the security event stream
By sending filtered events to SQS first, you decouple event ingestion from processing. EventBridge is responsible for delivering messages into the queue. Lambda is responsible for draining the queue and transforming those messages into downstream side effects.
This separation allows the workflow to be much more resilient. Issues in Slack, Lambda, or your code do not cause Okta events to vanish.
Step 4/ Turn Events Into Slack Alerts With Lambda
The Lambda function is triggered whenever messages land in the SQS queue. Its responsibilities are straightforward but important:
-
Parse the Okta event payload: Extract key attributes like the user, the actor who performed the action, timestamps, and any relevant context (such as the reason for suspension, if available)
-
Normalize the data: Map the raw Okta fields into a consistent internal structure so you can evolve the Slack message format over time without rewriting every consumer
-
Render a Slack friendly message Use a Slack Block Kit to generate a readable, structured notification that is easy to parse. Think of this as a tiny presentation layer that sits on top of the raw event
-
Send the notification Use the Slack bot token you should have already have created to post into your dedicated #okta-offboarding-alerts channel.
This is also the natural place to extend the workflow over time. Once the event is in Lambda, you can:
- Enrich the payload with data from other systems
- Spread out to additional services, such as ticketing tools (e.g, Jira Service Management, Zendesk, etc) or HRIS Systems for a more traditional offboarding workflow where HR/People teams are involved
- Trigger remediation tasks, such as revoking access to specific resources or forwarding emails and drives to managers during the offboarding process
The important thing is that the event driven plumbing stays the same. Only the Lambda logic evolves.
Here is a Python script I’ve created that will processes Okta user lifecycle events from SQS, formats Slack notifications and acts as a bridge between our AWS services.
Core Workflow:
- Consumes user.lifecycle.suspend and user.lifecycle.deactivate events from SQS
- Extracts user context, admin actor, and timing details
- Formats structured Slack messages with clear visual indicators
- Handles failures gracefully with retry capabilities
Next, let’s integrate our lambda_function.py with our Terraform configuration. You can zip this file from your working directory using:
zip -r lambda_function.py lambda_function.zipOn the Lambda side, the IAM policy sticks to least privilege. the function can read messages from the specific SQS queue and write logs to CloudWatch, and that is basically it.
The SQS event source mapping points to a Lambda alias (for example live) instead of $LATEST. That gives you a stable target for the queue while you ship new versions in the background. You can test a new version, shift the alias when you are ready, and avoid breaking the integration every time you deploy.
Runtime settings are tuned for this workflow as well. A 15 second timeout and a batch size of 10 messages give a good balance between throughput and fast failure detection. If Slack or a downstream dependency has trouble, the function fails quickly so SQS can handle retries and backoff, rather than sitting on hung invocations.
In AWS, you’ll see the Lambda function okta-event-workflow and a corresponding alias. That alias is what the rest of the pipeline targets, so we can update the Python code or Terraform configuration and then move the alias to the new version when we are ready, instead of pointing everything at LIVE.
At this point, Okta events are flowing through EventBridge, SQS, and Lambda, and the only thing left is alerting visibility. Here is the Slack message that lands in #offboarding-okta-alerts when a user is suspended or deactivated by an IT Admin from the Okta console, including the key details the team needs at a glance.
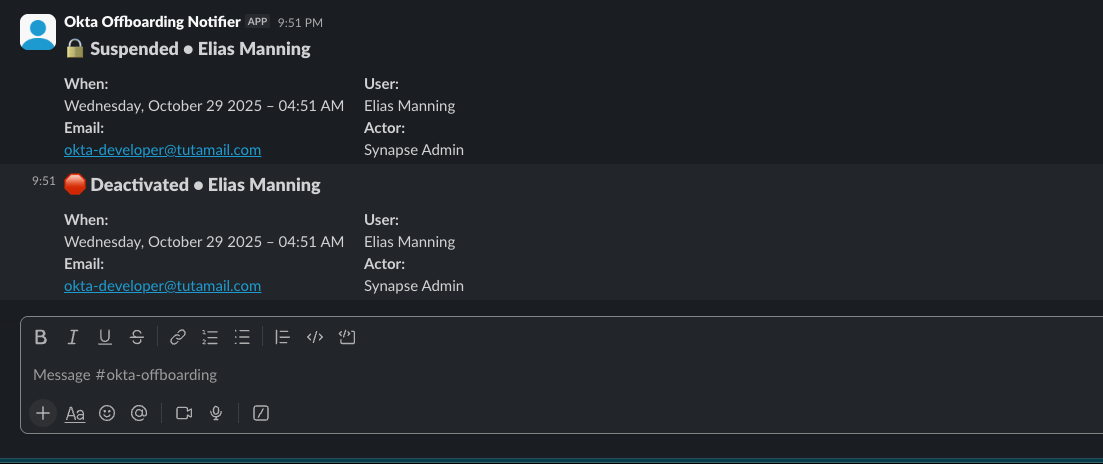
Conclusion: Turning Identity Events Into Production
By the end of this pipeline, you have moved from a closed, low code workflow to a fully observable, event driven, serverless automation that lives alongside the rest of your infrastructure as code.
Instead of a visual canvas buried inside Okta, identity events are now treated as structured streams entering your AWS environment. EventBridge handles routing, SQS gives you durable, retry friendly delivery, and Lambda acts as the worker that turns those events into Slack alerts. The entire stack is described in Terraform, which means you can version it, review it, and promote it across environments just like any other piece of infrastructure.
Although this walkthrough focuses on offboarding alerts, the pattern is general. Any identity driven workflow that benefits from real time visibility and reproducibility can be mapped onto the same architecture. High value security events like MFA changes or admin role assignments, compliance reporting pipelines, or even lightweight monitoring of app assignments and risky changes in your IdP.
Cost and scaling notes
One of the nice side effects of this design is that it is extremely cost efficient for typical IT workloads. EventBridge handles ingestion and routing, SQS provides buffering and durability, and Lambda runs short lived functions over small JSON payloads. At normal Okta system log volumes, that usually translates to a very small monthly bill. roughly pennies to a few dollars per month depending on how much you fan out events.
In my case, I worked with our team’s AWS rep to apply credits to this setup, so the entire proof of concept and early iterations ran at effectively zero cost. That made the experiment easy to justify, and IT leadership was happy to get better visibility without a new line item in the budget. Because everything is fully serverless and event driven, it also scales horizontally by default. If there is a spike in offboarding activity or bulk changes in Okta, SQS and Lambda absorb the load without any manual resizing.
Security and compliance considerations
This pipeline sits directly in the path of identity events and access changes, so security posture is non negotiable.
Secrets should be treated like any other sensitive token. Stored in AWS Secrets Manager or some sort of cloud service vault (I like Doppler). Access to those secrets should be limited to the Lambda execution role and a small set of operators who can rotate them.
IAM stays strictly least privilege. The Lambda role only needs to read from the specific SQS queue, read the Slack secret, and write logs to CloudWatch. EventBridge and SQS policies should be scoped so only Okta Log Streaming can write into the partner bus, and only the offboarding rule can publish to the queue, avoiding wildcards unless there is a very specific reason.
This design also helps with audit and compliance. Every offboarding event becomes a structured, timestamped alert in Slack, and the same events can be mirrored to S3 or CloudWatch for long term storage. Terraform plans, Git history, and pull requests form an audit trail for changes to the pipeline itself. With basic alerting on DLQ growth, Lambda errors, and aging SQS messages, you get fast feedback if events stop flowing from Okta to Slack instead of the pipeline quietly breaking in the background.
Future enhancements - Closing Out
This event driven workflow is intentionally narrow. It aims to solve one valuable problem well instead of trying to replace every Okta Workflow on day one. Once it is stable and could be integrated with other SaaS tools, there are several natural ways to extend it without rewriting the core pattern or abandoning the event driven design.
One obvious improvement is automatic ticket creation. Instead of only posting into Slack, the Lambda function could be built to also open tickets in your ITSM tool and attach the Okta event payload so security, IT, and HR have full context for each offboarding for “paper trail”.
Another is HRIS integration. The same event stream can be cross checked against HR data to flag drift, like users deactivated in Okta but still active in HR, or vice versa. At a previous org, we had a Leave Of Absence policy where employees had access revoked temporarily based on instructions from Legal. A pipeline like this could be wired to the HRIS so that an LOA event automatically triggers suspension in Okta without fully deprovisioning the account.
You can also turn this into a data and analytics feed by landing a copy of the events into S3 or another storage layer. That opens the door to dashboards for offboarding trends, admin actions, risky changes, and long term access patterns.
Over time, the Lambda can grow extended automation hooks. Calling APIs to revoke access in downstream systems, integrating with developer platforms, Atlassian Suite or Google Workspace, updating VPN or SSO providers, or kicking off longer running workflows with Step Functions when you need orchestration and approvals.
Through all of that, the core idea stays the same. Treat Okta as an event source, use AWS as the processing plane, and grow your automation surface area as the environment matures, without giving up the benefits of infrastructure as code and event driven design.